

Photo by Manuel Nägeli on Unsplash
Now that we can package our microservices into containers, we have a convenient way to store, transfer, and deploy our services, but we still don't have an application. All we have at this point is a suite of disparate containerized services. What we need is something that can bring all these services together and automate the deployment, management, and scaling of each of these services. What we need is a
Container Orchestrator.

Docker Swarm is an open-source orchestration platform created by the same team who brought you the Docker platform and is the native clustering engine for Docker containers. Because it is native to Docker, any tool that work with Docker containers will run also with Swarm. Swarm provides a simple configuration model the can aggregate a pool of Docker hosts into a single, virtual host while still ensuring that each container is isolated from other containers.
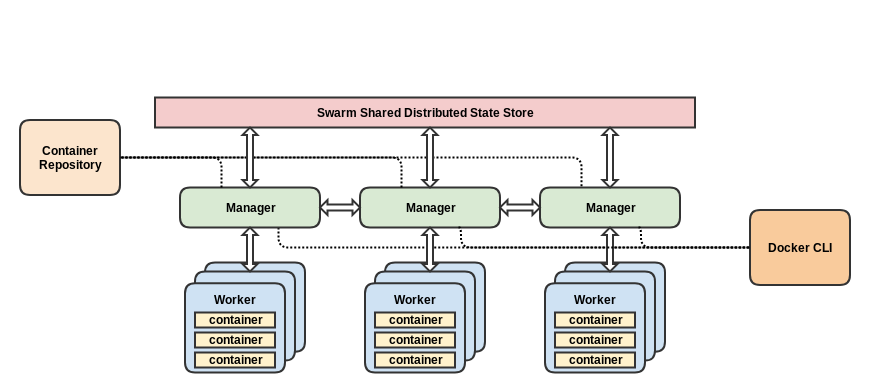
A Swarm cluster manages individual services within an application. It uses Docker Compose YAML templates to configure the cluster to scale individual services and is responsible for managing the entire cluster. The Swarm Manager node assigns each service a unique DNS name and is responsible for load-balancing the service's replicas by routing individual service requests using an internal DNS Server embedded in Swarm.
When choosing Docker Swarm, it is important to remember that it is platform dependent. While Docker is supported on Windows and Mac OSX, Docker Swarm only works on Linux. Additionally, Docker Swarm provides only basic monitoring information about its containers and also lacks an easy way to connect containers to storage.
 Kubernetes (a.k.a.
K8S) is an open-source container orchestration platform that was originally created at Google and is currently being maintained by the
Cloud Native Computing Foundation.
Kubernetes (a.k.a.
K8S) is an open-source container orchestration platform that was originally created at Google and is currently being maintained by the
Cloud Native Computing Foundation.
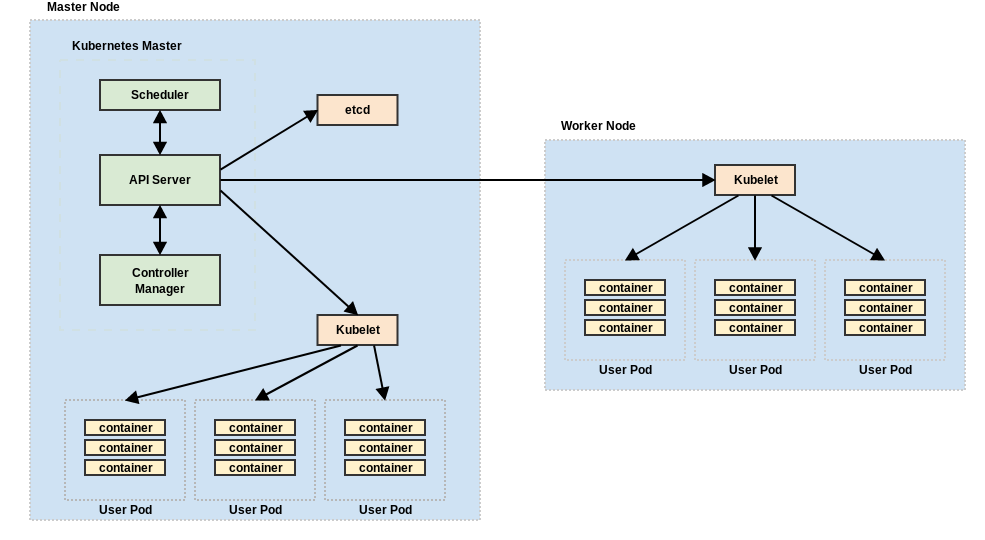
Kubernetes can be viewed from two perspectives: the Control Plane and Node Management.
etcd- is an open-source distributed key-value store that provides a reliable way to store data across a cluster of machines. It is built to survive network partitions and machine failures and is used by Kubernetes to provide a consistent highly-available backing data store for the cluster.
API Server- Kubernetes exposes a RESTful API interface for both internal and external use. This interface is the primary channel for administration.
Scheduler- The scheduler is responsible for selecting which node a container service will run on. This scheduler monitors resource utilization of each node to prevent excessive workload on any particular machine.
Control Manager- The control manager works in conjunction with the API server to create, update, or delete managed resources.
kube-proxy- the kube-proxy provides both network proxy and load balancing services to provide traffic management and communication routing to individual containers.
cAdvisor- is an agent that monitors and collects system resource utilization and performance metrics (e.g., CPU, memory, networking, file I/O, etc.) on each node container. This information is used by Kubernetes to identify containers that need to be scaled or that are consuming excessive resources.
When multiple containers need to be deployed together, the pod is configured to bundle them together and manage them as a single unit each sharing the same hostname and IP address. By clustering these containers together, the pod can be easily be moved around the cluster. Kubernetes monitors each pod's health and will redeploy the pod if it becomes unresponsive.
Each controller follows the same basic pattern. Within each controller is a non-terminating loop that performs three tasks:
For a deeper understanding of how the controller process works, i refer you to Kubewatch, An Example Of Kubernetes Custom Controller which provides a good example of how to build a custom controller.
Container Orchestration
When we talk about orchestration, we are talking about automating the management of service containers. Management includes deployment, updates, health monitoring, failover, and scaling of individual containers to create the "application" from its component services. In this article, we introduce two orchestration platforms: Docker Swarm and Kubernetes.Container Orchestration with Docker Swarm
Docker Swarm is an open-source orchestration platform created by the same team who brought you the Docker platform and is the native clustering engine for Docker containers. Because it is native to Docker, any tool that work with Docker containers will run also with Swarm. Swarm provides a simple configuration model the can aggregate a pool of Docker hosts into a single, virtual host while still ensuring that each container is isolated from other containers.
Docker Swarm Architecture
A Swarm cluster manages individual services within an application. It uses Docker Compose YAML templates to configure the cluster to scale individual services and is responsible for managing the entire cluster. The Swarm Manager node assigns each service a unique DNS name and is responsible for load-balancing the service's replicas by routing individual service requests using an internal DNS Server embedded in Swarm.
When choosing Docker Swarm, it is important to remember that it is platform dependent. While Docker is supported on Windows and Mac OSX, Docker Swarm only works on Linux. Additionally, Docker Swarm provides only basic monitoring information about its containers and also lacks an easy way to connect containers to storage.
Container Orchestration with Kubernetes
Declarative vs. Imperative
One of the great strengths of Kubernetes is its support for a Declarative Management model. Unlike the Imperative Management model which requires the user to work out the sequence of commands to achieve a desired state, The Declarative model only requires us to declare what the desired end state of the application should be, and Kubernetes works out what operations need to be performed to realize that state. This approach eliminates much of the administration involved when deploying and scaling containerized applications across a cluster of servers. It also provides auto-replication for scaling and auto-restart of crashed containers.Kubernetes Architecture
Kubernetes is built around a Master-Slave pattern. The Master is the machine (physical or virtual) that is responsible for controlling a collection of Slave nodes.Kubernetes Master
The master receives all administrative commands and execute the appropriate commands on the cluster nodes to fullfil the administrative commands. Each master can be run on a single node or across a cluster of machines in a high-availability model which ensures fault-tolerance and reduces downtime.Kubernetes Slave Nodes
The master is responsible for assigning tasks to slave nodes. Slave nodes (often referred to as workers or minion nodes) are responsible for executing the application's containerized services.
Kubernetes can be viewed from two perspectives: the Control Plane and Node Management.
Control Plane
The Control Plane is made up of several components: etcd, API Server, Scheduler, and Control Manageretcd- is an open-source distributed key-value store that provides a reliable way to store data across a cluster of machines. It is built to survive network partitions and machine failures and is used by Kubernetes to provide a consistent highly-available backing data store for the cluster.
API Server- Kubernetes exposes a RESTful API interface for both internal and external use. This interface is the primary channel for administration.
Scheduler- The scheduler is responsible for selecting which node a container service will run on. This scheduler monitors resource utilization of each node to prevent excessive workload on any particular machine.
Control Manager- The control manager works in conjunction with the API server to create, update, or delete managed resources.
Node Management
kubelet - kubelet is responsible for running and monitoring the health of containers for a given node. It handles starting and stopping containers as directed by the control plane.kube-proxy- the kube-proxy provides both network proxy and load balancing services to provide traffic management and communication routing to individual containers.
cAdvisor- is an agent that monitors and collects system resource utilization and performance metrics (e.g., CPU, memory, networking, file I/O, etc.) on each node container. This information is used by Kubernetes to identify containers that need to be scaled or that are consuming excessive resources.
Pods
Kubernetes is built around the idea of a Pod. Each pod represents a set of processes running in the cluster. In its most basic form, a pod represents a single container instance, its storage, a unique IP address, and the containers configuration options.When multiple containers need to be deployed together, the pod is configured to bundle them together and manage them as a single unit each sharing the same hostname and IP address. By clustering these containers together, the pod can be easily be moved around the cluster. Kubernetes monitors each pod's health and will redeploy the pod if it becomes unresponsive.
Controllers
To achieve Declarative Management, Kubernetes runs a "pluggable" set of controllers, each responsible for monitoring the current state of a cluster resource and ensuring that it matches the declared state. Currently, Kubernetes supports two types of controllers; Core controllers which ship with Kubernetes, and Custom controllers which extend the Kubernetes API beyond its default complement.- Core controllers are responsible for ensuring that the basic elements of the application (e.g., Node Controller, Replication Controller (pods), Endpoint Controller, etc. ) are available and provision new instances when they fail.
- Custom controllers allow third-parties to develop controllers to support application-specific use cases.
Each controller follows the same basic pattern. Within each controller is a non-terminating loop that performs three tasks:
- retrieve desired state
- retrieve current state
- execute commands to achieve the desired state.
For a deeper understanding of how the controller process works, i refer you to Kubewatch, An Example Of Kubernetes Custom Controller which provides a good example of how to build a custom controller.

Twitter
Facebook
Reddit
LinkedIn
Email